How fast can you process 6500 TPS? High Performance Shopping is faster

Shopping is the first step of the reservation. It refers to the act of exploring and comparing various flight options to secure the best deal and the most convenient travel itinerary. Typically, this includes entering the departure and arrival cities, travel dates, and the number of passengers.
The High-Performance Shopping (HPS) shopping engine produces the largest share of shopping solutions at Sabre, delivering nearly 70% of all generated results. HPS optimisations refer to strategies and techniques to enhance the HPS’s efficiency, speed, and effectiveness.
These optimisations are critical for both Airline Solutions and Travel Network customers to keep the average response time below 1.5 seconds for TN and below 1 second for AS customers. Each CPU cost reduction brings significant savings, given that the whole HPS farm consists of ~1000 VMs available in 5 GCP regions in the US.
HPS offers a top-notch performance by using a rule-based shopping algorithm. This allows HPS to handle a high volume of traffic, roughly ~560M requests daily (~6500 TPS) — CPU dashboard (sabre.com). The engine evaluates specific conditions and executes corresponding actions based on predefined business logic.
HPS data access
Another shopping engine has difficulty handling large amounts of data currently stored in an SQL database.
For example, there are over 300M active fares, 15M schedules, 22M records in Table 989, and so on. It is clear that loading data from the database within a specified timeout, such as 8 seconds, is not feasible.
A classic solution to this problem is to use an additional layer between the application and the database: an internal cache for loaded data. If the data for the requested keys are not available in the cache, the application must load data from the database and put it into the cache. Future requests can then use this data without accessing the database.
But there are some drawbacks of this approach:
- warmup stage: if no data exists for the wanted key, the application must query the database for missing data, which may lead to a timeout because retrieving data takes some time. Until all the data are processed, requests may time out.
- lock contention: this may limit scalability because many transactions must compete with access to cache.
HPS uses different strategies; all data are stored in binary blocks.
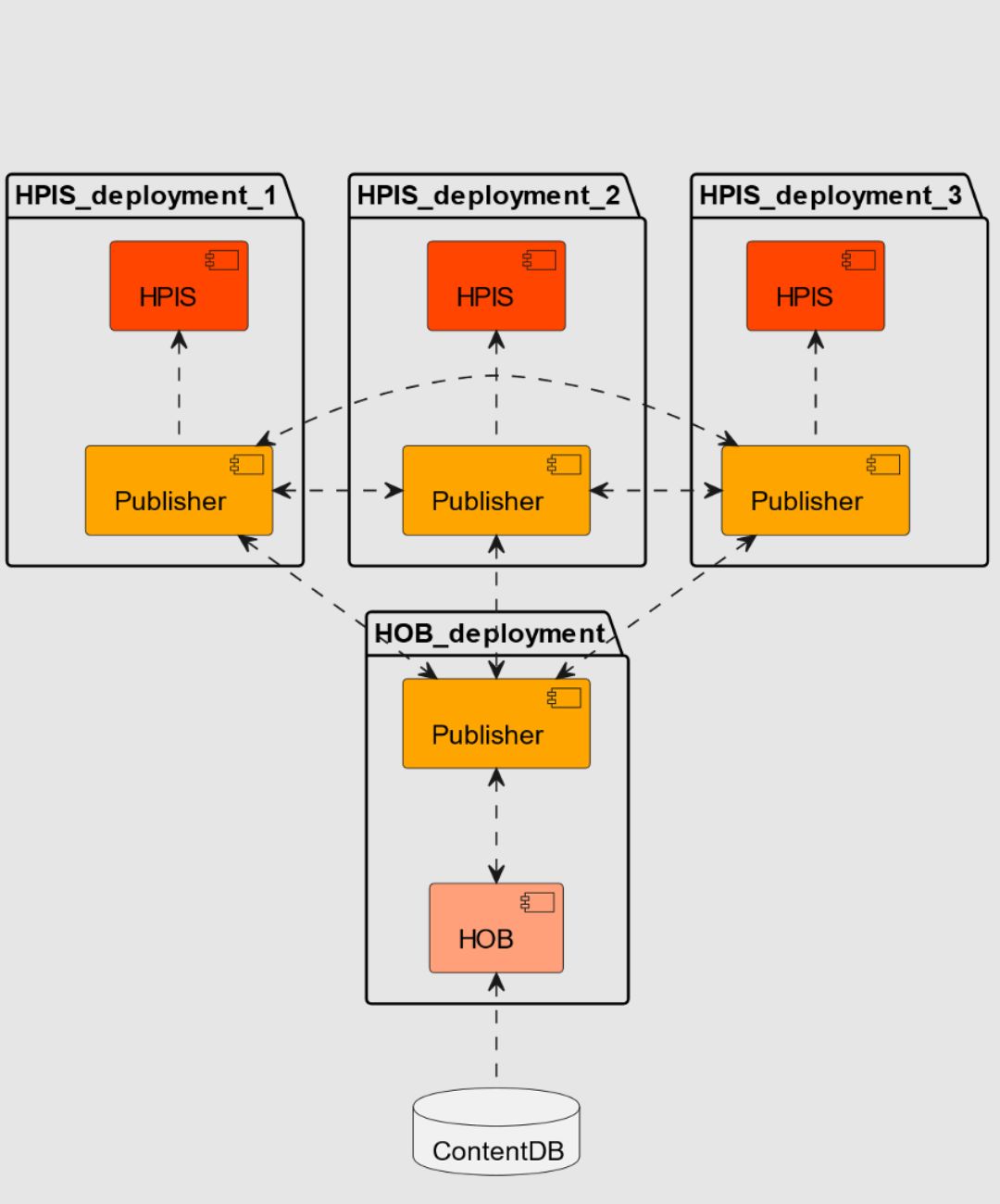
There is only one application for a group of processing nodes (HPIS) that produces binary data: HOB — HPS Object Builder. HOB loads data from the database and transforms it into a binary representation. After that, all binary blocks are distributed to processing nodes.
Advantages:
Binary blocks are ordinary files mapped into memory by POSIX shared memory and used as ordinary C/C++ structures. There is no time-consuming serialisation/de-serialisation. The application does not require a warmup stage; all data are available immediately. Also, there is no lock contention because binary blocks are mapped into memory as read-only.
Nevertheless, there are drawbacks:
– all data from the database must be kept in memory.
It may seem that keeping data in memory in case of many records is not a good idea. Still, we achieved good results thanks to some optimisations, like using binary fields, packed representation for fixed strings, in-house containers, and finding duplicated data. Initially, all data consumed about 80GB of memory, and the amount of data was smaller (for example, about 200M active fares). After optimisation, all data takes about 40GB, and this size has been stable for years.
Interestingly, most of the data used is not occupied by one-to-one records from the database but by additional mappings designed to improve processing efficiency , for example, prebend R2 records to speed up matching in HPIS.
– updating modified data may be a challenge.
To solve this problem, HOB invalidates only changed data, and only modified blocks are sent to processing nodes. If data needs to be refreshed in processing nodes, it is done on the fly: modified blocks are mapped into memory. New transactions use fresh data, while old data are removed from memory if they are no longer needed.
– transferring blocks between HOB and HPIS.
The total size of binary blocks is about 40GB, and even with incremental updates, which may take, for example, 5GB, transferring such a large amount of data may be time-consuming. To resolve this issue, all binary blocks are compressed using XZ compression, which shrinks the total size to 5GB and incremental updates to hundreds of MB. An additional application called “publisher” is used to exchange binary blocks between HOB and HPIS. Publishers use the BitTorrent protocol for peer-to-peer binary data sharing.
Under the hood:
SQL table:
TABLE SVCFEESFAREID (
VENDOR VARCHAR2(4) NOT NULL,
ITEMNO NUMBER(11) NOT NULL,
SEQNO NUMBER(11) NOT NULL,
VALIDITYIND VARCHAR2(1),
FAREAPPLIND VARCHAR2(1),
OWRT VARCHAR2(1),
RULETARIFF NUMBER(6),
RULE VARCHAR2(4),
FARECLASS VARCHAR2(8),
# …
)
C++ code
class SvcFeesFareId: public DatableExpOnly
{
// …
uint32_t seqNo_{0u};
RoutingNumber routingNumber_;
RuleCode rule_;
FareClassPattern fareClassPattern_;
FareAmountInfos fareAmountInfos_;
TariffNumberType tariffNumber_{NONE_TARIFF_NUMBER};
// …
};
using Key = std::pair<VendorCode, ItemNumber>;
NGS_TYPEDEF((shm::vector_map<SvcFeesFareIdTableKey, SvcFeesFareId>), SvcFeesFareIdTable);
shm is a wrapper for POSIX shared memory. Binary data for SVCFEESFAREID are ordinary files:
[GCP RedHawk]$ ls -lh /dev/shm/DbSvcFeesFareId
-rw-r–r–. 1 user group 134M Jun 28 03:52 /dev/shm/DbSvcFeesFareId
Most of the identifiers in the database have fixed sizes, and ATCPO defines the format of those identifiers. For example, the airport name is coded by three characters, and a single character must be an uppercase letter or digit, such as KRK or JFK. Instead of using 3 bytes to store the name of the airports, HPS packs such names into 2 bytes and uses integral type for storing:
struct AirportCodeParams : util::AlphaCodeParams
{
static constexpr std::size_t MIN_SIZE = 3;
static constexpr std::size_t MAX_SIZE = 3;
};
class AirportCode : public util::Code<AirportCodeParams>
AirportCode is stored using uint16_t. This saves space and speeds up comparison.
Hybrid threads pool
HPS uses a hybrid thread pool approach. That is, instead of using a global thread pool for all transactions, HPS creates a fixed-size local thread pool for each new transaction.
Creating new threads is not very efficient, especially for nowadays multi-core architectures (costly syscalls). HPS uses so-called thread rental, which is a global collection of ready-to-use threads.
For new transactions, HPS rents some threads from threads rental and returns at the end.
The fixed size of the local threads pool allows better resource usage control; for example, 6 threads are assigned for preprocessing.
Sometimes, HPS can request additional threads if there are free ones. For example, when generating an itinerary, there may be 10 carrier priority queues processing.
Each carrier can be processed in a separate thread, so if there are 6 threads at the beginning, HPS can request additional ones, for example, 4. Depending on server usage, it may get 0-4 new threads from rental.
Threads are returned immediately if not needed; for example, only 3 carriers remain.
HPS memory allocator
HPS uses a dedicated memory allocator alongside the general-purpose jemalloc allocator.
The custom arena allocator was developed to leverage the specifics of HPS processing to improve memory allocation/deallocation performance.
The HPS server is a program that serves incoming HTTP or custom protocol message requests and processes them in parallel at some isolation level.
For the purposes of this description, an isolation level can be simplified to a situation where no transaction interacts with or affects the state of other transactions.
Each transaction has its own stateful individual arena allocator, which exists for the duration of the transaction. A single instance of arena allocator maintains thread-local allocators. Access to an allocator’s thread-local state from a thread that is not its owner is restricted to situations where an allocated memory in one thread is freed by another thread. These assumptions allow the allocator to be implemented as lock-free, avoiding the need for extra mechanisms to handle the ABA problem and thus reducing metadata overhead. Additionally, this approach enhances locality and mitigates false sharing problems.
All arena instances use a global pool of 64MB superblocks that are allocated on demand from an arena allocator. The pool maintains a limited maximum number of superblocks between transactions. On the one hand, this reduces the server process’s memory usage when the load is low, and on the other hand, it decreases the number of system calls, which can be significant at high transaction rates.
In the case of a hierarchy of objects allocated within a single arena, when none of the objects require releasing external resources, individual object deallocation is not needed. At the end of the transaction, the superblocks are returned to the global pool without being traversed through the object hierarchy to be freed, thereby eliminating the need for memory access.