Approach for CI-CD in Machine Learning: A Retail Intelligence Use Case

Published
on
 April 22, 2022
April 22, 2022
An enterprise application software is composed of multiple layers, components and verticals. While until most recently, the foundations of these systems comprised of elements like databases, web-engines, MQs, User interface etc., machine learning based sub systems have made a significant foray into the ecosystem. Like other auxiliary systems that make up part of the bigger ecosystem, sub-systems that implement machine learning practices should also adhere to common software development and deployment strategies like CI-CD covering all functional and nonfunctional facets like code testing, verification, security and portability.
Level pegging of a ML system’s CI-CD strategy to a web application system in all characteristics would not be a correct strategy to follow.
Retail Intelligence is Sabre’s pilot initiative to operationalize systems backed with machine intelligence on production, helping airlines to capitalize on revenues generated from dynamic bundle offers. As part of the initiative, the team formalized a generic approach to implement CI – CD practices for ML project.
This article details our strategy and implementation in applying CI and CD practices behind the Retail Intelligence tool’s Machine Learning Systems.
Continuous integrations and Continuous Delivery / Deployment have become dominant facets of software engineering. Before we dive into the strategy and implementation of CI-CD for machine learning systems, it’s imperative to understand what CI – CD is, and how it might differ for a ML system.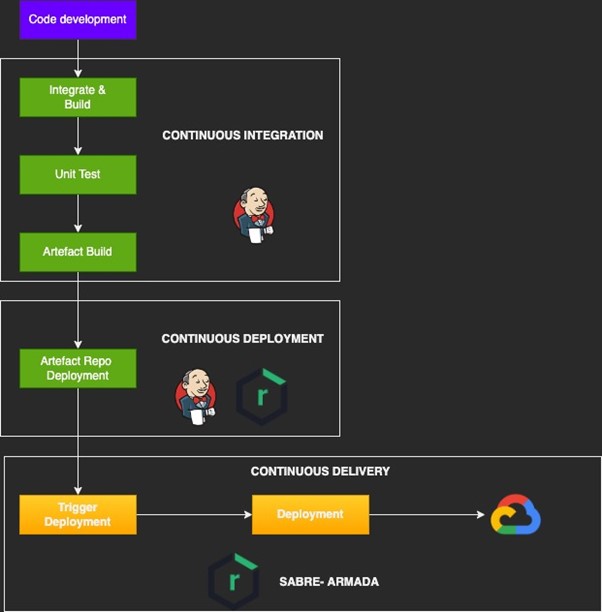
Google recommends using GCP based services to implement CI-CD for ML based projects. The block below highlights the services that can be used: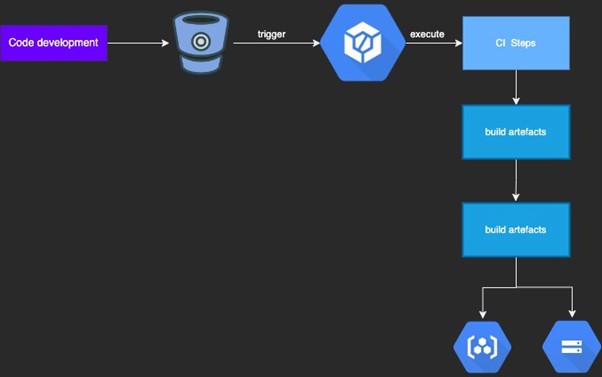 The suggested approach has the following challenges, when implementing Sabre’s standard practices:
The suggested approach has the following challenges, when implementing Sabre’s standard practices:
 Key Highlights:
Key Highlights:
In line with the above strategy the flow for implementing CI – CD – CD for ML Systems as part of Retail Intelligence is as follows: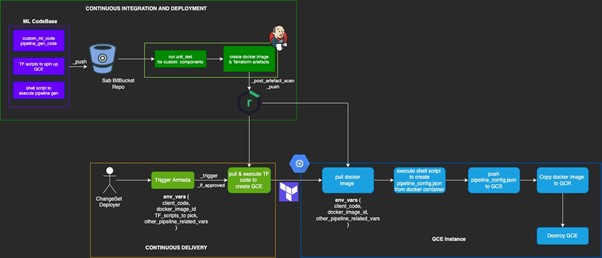 Core Constituents:
Core Constituents:
The above approach capitalizes Sabre’s defined CI – CD best practices in creating standards practices for ML system’s development to delivery lifecycle. As processes are further evolved this approach can be more compact and agile.
CI – CD & Machine Learning
Continuous integrations and Continuous Delivery / Deployment have become dominant facets of software engineering. Before we dive into the strategy and implementation of CI-CD for machine learning systems, it’s imperative to understand what CI – CD is, and how it might differ for a ML system.
What is CI-CD – CD?
While CI and CD are two different concepts, their lineage and correlation make them almost inseparable in contemporary times.
- CI (Continuous Integration) refers to an automation process, that facilitates automated code build, unit / module / integration testing, which are then merged to a shared repository that has defined branches (versions). These branches / versions would eventually be deployed in production.
- CD (Continuous Deployment) is a process that is executed in conjunction with CI where the built and tested code are compiled to create artefacts like war, jar, docker image etc. and pushed to an artefact registry like Nexus.
- CD (Continuous Delivery) refers to activities that automatically (via a change set management tool) deploys the code to production location
CI CD in a Web Application: A known world example
The core constituents of a web application can be categorized as follows:- Data Store: Relational / no -SQL format cloud or on-premises data bases like Oracle, MySQL etc. These have static URLs on which connection is generally made using JDBC connection by a consumer application
- Messaging Infra: MQ’s used by application to communicate between components
- Application Artefact: A docker or war files that takes in environment variable for a one time connection setup like DB, MQ, message formatting set up and is good to receive requests and send back meaningful responses
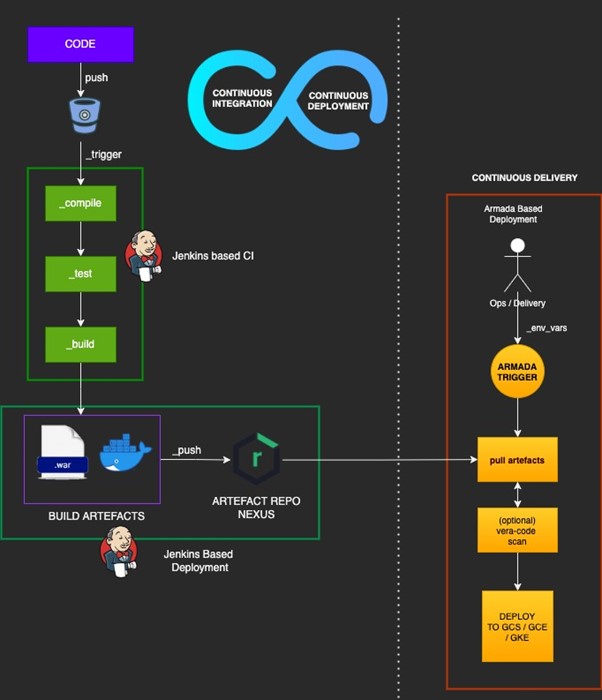
CI CD for a Machine Learning Application
What constitutes Machine Learning based Application Development?
Our ML solution uses the below components –- TFX (TensorFlow Extended) are components that form part of the ML pipeline. Components like ExampleGen, StatisticsGen, Trainer, Evaluator etc. are used in conjunction to create a ML Pipeline. Some of these components like Trainer and Transformer run custom code. The TFX components and the custom code components are written using Python.
- Kubeflow is the orchestrator for ML-Pipeline. It is a compiled configuration file that records pipeline components, their lineage and run configurations, which run on infrastructure that facilitates machine learning. Examples of these infrastructure can be GKE cluster, AI Platform, Vertex AI on GCP and SageMaker, EKS on AWS.
- Docker containers are used to package and run the ML custom code and components. Kubeflow pipeline configuration file is updated with the Docker URI. The pipeline config and docker image are used by infrastructure for training pipelines.
- GCS and GCR: Since our ML pipelines are run on GCP, the ML artefacts are made accessible by uploading them on GCS (Kubeflow pipeline config) and GCR (Docker image) for ML infra services to run the pipelines.
- Vertex AI Platform Pipelines provides us managed infrastructure services to run Kubeflow pipelines. Here Kubeflow jobs are triggered that run continuous ML pipelines.
What Makes this Different?
Unlike web applications, Machine Learning models are the end products that are deployed at a production endpoint. These models are prepared in the working environment using ML pipelines relying on standard ML libs and APIs along with some custom codes, training data and the distributed computing infra underneath that work in harmony. Thus, the containerized code and configurations that are used to create these models become the primary CI-CD focus. The model that is eventually created in your environment might require a grant mechanism to be the defaulted version at hosting endpoints, something that we are not covering within the scope of this document.Google’s Recommendation
Google recommends using GCP based services to implement CI-CD for ML based projects. The block below highlights the services that can be used:
The suggested approach has the following challenges, when implementing Sabre’s standard practices:
- Leaving Sabre’s CI-CD best practices and adopting an entirely different non-vetted strategy
- Changeset management tools for vetted delivery like Armada would be missed out on
- Vetted tools for artefact scan like vera-code might have to be skipped
- Piggy banking on Google’s build system makes our delivery systems very cloud native
- GCP’s Vertex AI does not have access to Sabre Nexus repo
- Pipelines configurations must be created per client per environment wise. Precompiling these configurations would mean higher build time and unwanted artefacts generation
Key Highlights:
- Unlike a Java based web application, where a JAR or the docker image would be the primary entity to be deployed as part of CI CD practices, for ML, the code that creates the pipeline would be treated as the intermediate primary entity to be deployed and delivered
- Sabre Nexus repo is an intermediary storage repository and the docker image would be copied to GCR, since Vertex does not have access to Sabre Nexus repos. This step can evolve as access processes take more robust shape
- Armada is Sabre’s changeset management tool in verifying and validating artifact delivery
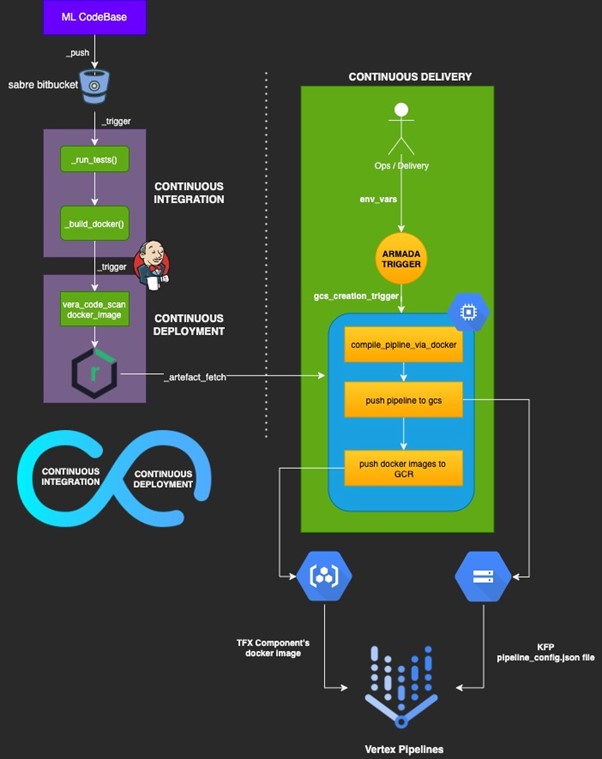
Implementing CI – CD for Retail Intelligence ML
In line with the above strategy the flow for implementing CI – CD – CD for ML Systems as part of Retail Intelligence is as follows:
Core Constituents:
- ML Custom code and pipeline gen codes: Codes that are used in ML training pipeline. These components are part of the docker image that is created and used in running pipelines on Vertex
- TF (Terraform) codes that are used to create GCE instance. This instance would be used to compile and create pipeline configuration files from the docker image
- Shell Script: Orchestrating pipeline creation and artefact deployment on GCE and GCR. Script would be executed in GCE
- Docker image and TF code would be scanned using the vera code scanner, thus all the code layers before deployment and delivery would be scanned
- The base image of TFX used to create the final docker image would be uploaded to Sabre Nexus repo and to be picked from there to create the final docker image that would be pushed to Sabre Nexus Repo
Summary
The above approach capitalizes Sabre’s defined CI – CD best practices in creating standards practices for ML system’s development to delivery lifecycle. As processes are further evolved this approach can be more compact and agile.